MAIC
文章主要参考MAIC(Matching-Adjusted Indirect Comparison)领域的首篇文献[1]以及NICE DSU Technical Support Doucument 18[2]。也感谢甘磊师弟提供的PPT及R语言实现案例。
理论知识
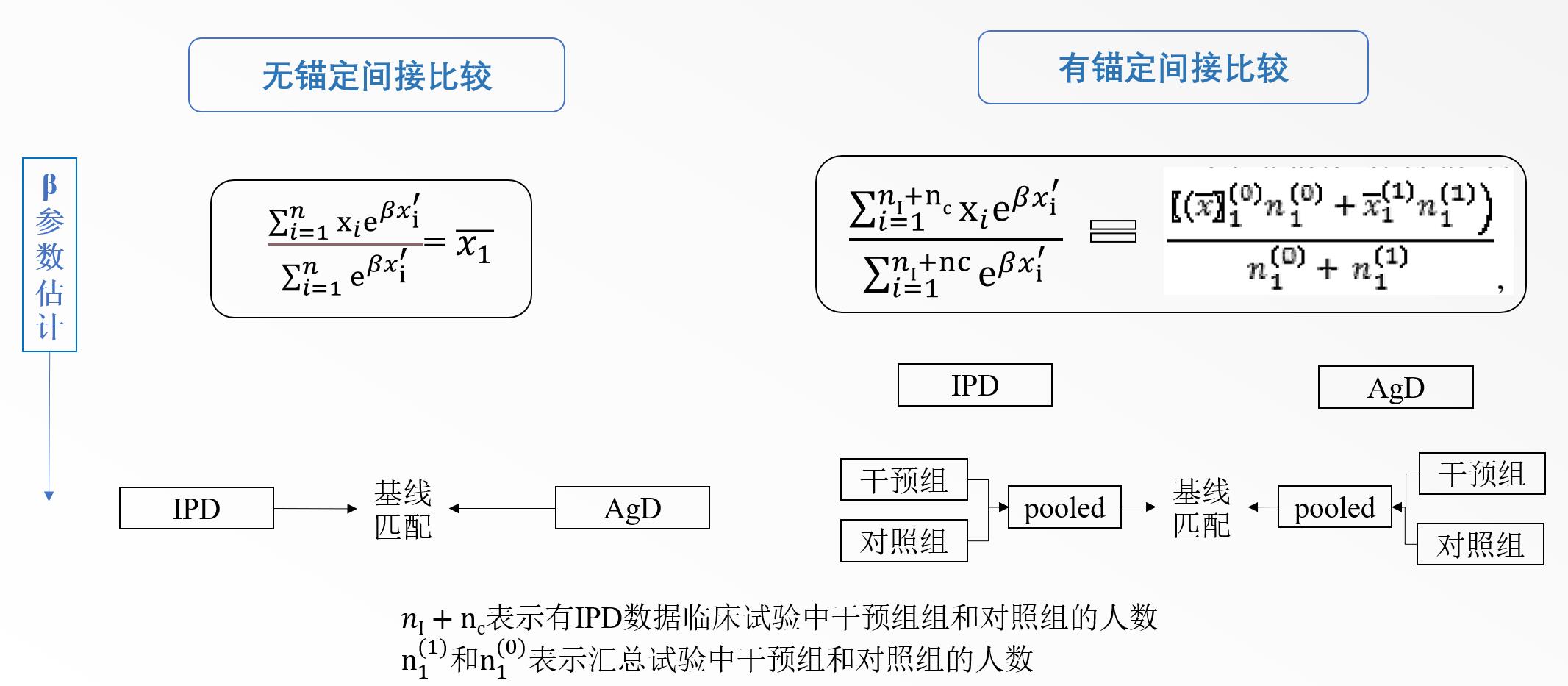
已知干预组患者的个体患者数据(IPD)和对照组患者的汇总数据。
则干预组和对照组的平均治疗效果的差值$\theta$为
$$ \hat{\theta}=\frac{\sum\limits_{i=1}^{n} y_i w_i} {\sum\limits_{i=1}^nw_i} -\bar{y_1} \tag{1} $$ 其中$\hat{\theta}$表示平均处理效应的差值;$y_i$表示有IPD数据临床试验的结果;$w_i$表示IPD试验中第$i$位患者的权重;$\bar{y_1}$表示汇总数据临床试验的结果。
公式(1)中,$w_i$不知道,需待求。
根据倾向性评分加权的原理,$w_i$等于第$i$个患者进入汇总数据试验($T_i=1$)的概率比上进入IPD数据试验组($T_i=0$)的概率。
$$ w_i=\frac{P(T_i=1|X_i)}{P(T_i=0|X_i)} \tag{2} $$
其中,$w_i$表示IPD试验中第$i$位患者权重,$P(T_i=1|X_i)$ 表示该患者在给定基线特征$X_i$的条件下,进入汇总试验组的概率,即倾向性评分(PS),$P(T_i=0|X_i)$ 表示该患者在给定基线特征$X_i$的条件下,进入IPD试验组的概率,也等于$1-P(T_i=0|X_i)$。
公式(2)中,$P(T_i=1|X_i)$和$P(T_i=0|X_i)$不知道,需待求。 假设如果有汇总数据组的个体数据,那么可用logistics回归计算
$$ P(T_i=1|X_i)=\frac{e^{\beta_0 + \beta X_i}} {1+e^{\beta_0 + \beta X_i}} \tag{3} $$
其中,$\beta$代表每个协变量的logistic的回归系数。
$$ P(T_i=0|X_i)=1- P(T_i=1|X_i) = \frac{1} {1+e^{\beta_0 + \beta X_i}} \tag{4} $$ $$ w_i=\frac{P(T_i=1|X_i)}{P(T_i=0|X_i)} =\frac{e^{\beta_0 + \beta X_i}} {1+e^{\beta_0 + \beta X_i}} / \frac{1} {1+e^{\beta_0+\beta X_i}}=e^{\beta_0+\beta X_i} {\tag5} $$
将公式(5)带入公式(1)中:
$$
\hat{\theta}=\frac{\sum\limits_{i=1}^{n} y_i w_i} {\sum\limits_{i=1}^nw_i} -\bar{y_1} =
\frac{\sum\limits_{i=1}^{n} y_i e^{\beta_0+\beta X_i}} {\sum\limits_{i=1}^ne^{\beta_0+\beta X_i}} -\bar{y_1}
$$
$$ =\frac{e^{\beta_0} \sum\limits_{i=1}^{n} y_i e^{\beta X_i}} {e^{\beta_0}\sum\limits_{i=1}^ne^{\beta X_i}} -\bar{y_1}= \frac{\sum\limits_{i=1}^{n} y_i e^{\beta X_i}} {\sum\limits_{i=1}^ne^{\beta X_i}} -\bar{y_1} \tag{6} $$
根据公式(6)我们发现,在计算$\hat{\theta}$时,$\beta_0$被消去了,也就是说我们无需估计出$\beta_0$,进一步我们也可以理解为$w_i=e^{\beta X_i}$。
至此,根据公式(6),我们得出IPD试验患者的权重等于$e^{\beta X_i} {\tag5}$ ,其中$\beta$未知,待求。
由于缺乏汇总实验数据的IPD,无法使用最大似然估计法(MLE)估计出$\beta$。因此使用矩估计法求$\beta$。
因为已知加权后两个试验(IPD数据试验和汇总数据试验)患者的基线应该是平衡的,即两组协变量均值之差为0, 所以得出公式(7)
$$ \frac{\sum\limits_{i=1}^{n} X_i w_i} {\sum\limits_{i=1}^nw_i} -\bar{X_1}=0 \tag{7} $$
其中,$\bar{X_1}$是汇总数据试验患者基线变量的均值。
将$w_i=e^{\beta X_i}$带入公式(7),得到 $$ \frac{\sum\limits_{i=1}^{n} X_i e^{\beta X_i}} {\sum\limits_{i=1}^n e^{\beta X_i}} -\bar{X_1}=0 \tag{8} $$
将公式(8)等式两边同乘第一项的分母,然后合并同类项,得到
$$ \sum\limits_{i=1}^{n} X_i e^{\beta X_i} - \sum\limits_{i=1}^{n}\bar{X_1} e^{\beta X_i} =\sum\limits_{i=1}^{n} (X_i-\bar{X_1}) e^{\beta X_i} =0 \tag{9} $$
假设公式(9)中的$\bar{X_1}=0$,其实也就是对IPD试验组每个患者的基线进行离差变化($X_i-\bar{X_1}$)即可满足此假设,得到公式(10)。
$$ \sum\limits_{i=1}^{n} X_i e^{\beta X_i} =0 \tag{10} $$ 注:公式(10)中的$X_i$是离差变换后的IPD试验组的基线特征。
这里我们引入目标函数$Q(\beta)$来求解$\beta$:
$$ Q(\beta)= \sum\limits_{i;t_i=0}^n X_i e^{X_i^T \beta} \tag{11} $$
因为等式(10)的左式实际上是公式(11)的梯度函数(一阶导函数),所以求公式(11)的极小值对应的$\beta$就相当于求解等式(10)。
而目标函数的二阶导函数(公式(12))对于所有$\beta$来说都是正定的,所以目标函数$Q(\beta)$是凸函数,且有全局极小值对应的唯一解。
$$ Q^{(2)}(\beta)= \sum\limits_{i;t_i=0}^n X_i X^T_i e^{X_i^T \beta} \tag{12} $$
基于此,可以使用牛顿迭代法(Newton-Raphson)求目标函数(公式(12))的极小值,也就解出了等式(10),能得出$\beta$,也就得到了IPD试验患者的权重值$w_i$。

理论部分终于完结了,撒花!🌺🌺🌺
接下来是R语言实现。
R语言实现MAIC
疾病背景:
- P:moderate to severe Psoriasis(银屑病)patients in North America
- I:Adalimumab(阿达木单抗-IPD)
- C:etanercept(依那西普)
- O:Psoriasis Area and Severity Index(银屑病面积及严重程度指数)
- S:No randomized, head-to-head clinical trial has compared adalimumab with etanercept for the treatment of psoriasis.
假设只有年龄属于效果修饰因子,性别属于预后变量。
第一步,将两组药物的数据输入
library(tidyverse)
mydata1<-tibble(id=1:10,
age=c(49,50,44,43,55,57,49,51,53,59),
gender=c(0,1,0,1,0,1,1,1,0,1),
outcome=c(7.0,7.7,6.0,6.8,7.2,7.5,8.0,6.3,7.2,7.9))
A.IPD<-mydata1
mydata2<-tibble(age.mean=53,
age.sd=1.290994,
N.male=4,
prop.male=0.8,
y.B.sum=37,
y.B.bar=7.4,
N.B=5,
varB=0.2)
B.AgD<-mydata2
第二步,建立Q(b)及其一阶导数和离差变换
#建立Q(b)函数
objfn<- function(β1,X){
sum(exp(X %*% β1))
}
#建立Q(b)一阶导数
gradfn<- function(β1,X){
colSums(sweep(X, 1, exp(X %*% β1), "*"))
}
#对基线特征进行离差
X.EM.0<- sweep(with(A.IPD, cbind(age, age^2)), 2,
with(B.AgD, cbind(age.mean, age.mean^2 + age.sd^2)), "-")
第三步,对$Q(\beta)$函数进行最小化来求出$\beta$的唯一解
print(opt1<-optim(par=c(0,0), fn=objfn, gr=gradfn, X=X.EM.0, method="BFGS"))
## $par
## [1] 36.0887332 -0.3398965
##
## $value
## [1] 2.764361
##
## $counts
## function gradient
## 91 33
##
## $convergence
## [1] 0
##
## $message
## NULL
第四步,计算权重值
β1<-opt1$par
wt<- exp(X.EM.0 %*% β1)
N.A<-c(10)
wt.rs<- (wt/sum(wt))* N.A #标准化权重
summary(wt.rs)
## V1
## Min. :0.000000
## 1st Qu.:0.005488
## Median :0.028501
## Mean :1.000000
## 3rd Qu.:1.151896
## Max. :6.374269
第五步,计算有效样本量
#画出调整后的权重的分布图
library(ggplot2)
qplot(wt.rs,geom="histogram", xlab="Rescaled weight", binwidth=0.25)
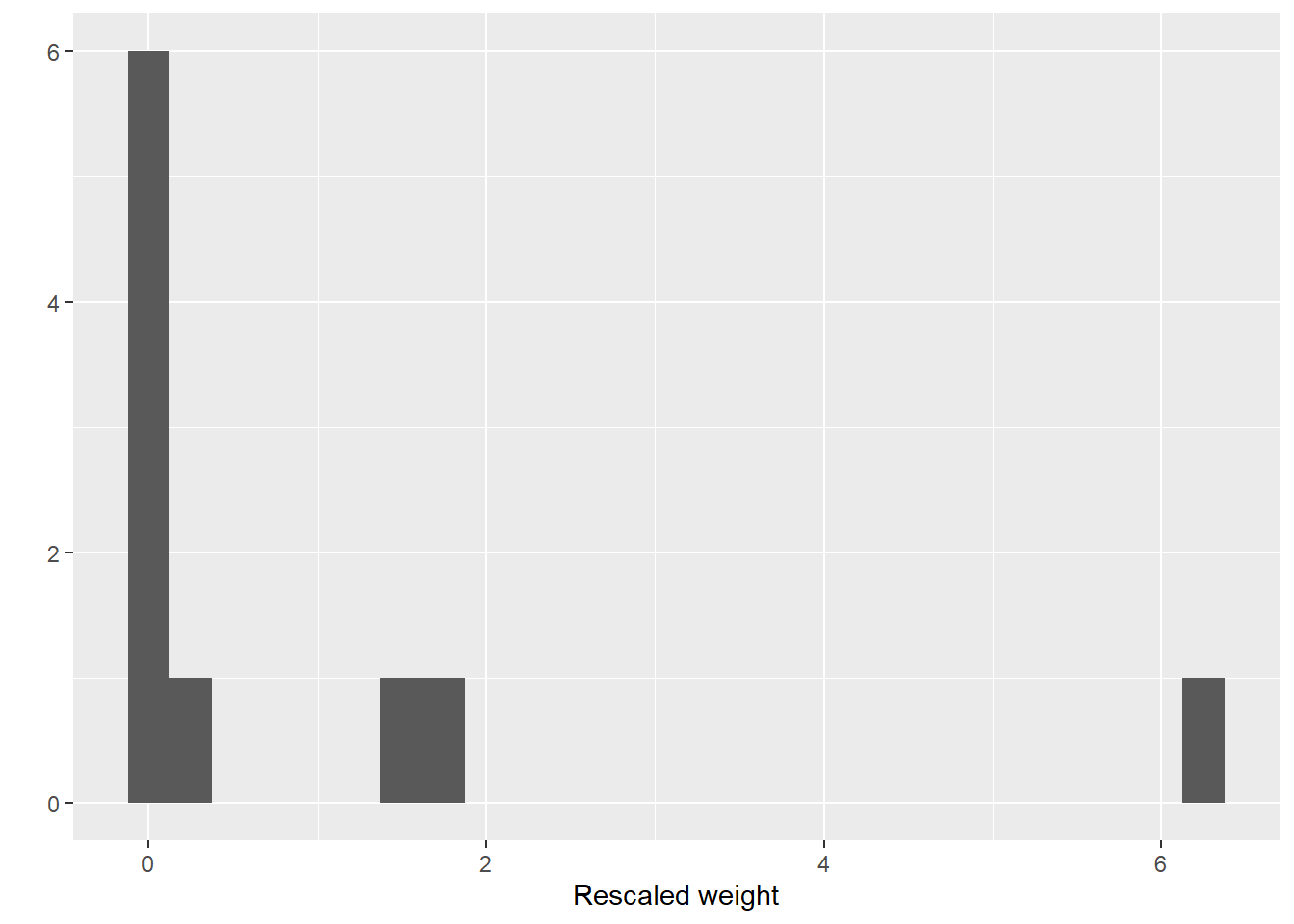
#计算有效样本量ESS
sum(wt)^2/sum(wt^2)
## [1] 2.164168
第六步,计算加权后的基线平均值
#计算加权后IPD试验的基线平均值和标准差
library(dplyr)
A.IPD %>%
mutate(wt)%>%
summarise(age.mean=weighted.mean(age, wt),
age.sd=sqrt(sum(wt/sum(wt)*(age-age.mean)^2)))
## # A tibble: 1 × 2
## age.mean age.sd
## <dbl> <dbl>
## 1 53.0 1.29
#汇总试验的基线平均值和标准差
B.AgD[, c("age.mean","age.sd")]
## # A tibble: 1 × 2
## age.mean age.sd
## <dbl> <dbl>
## 1 53 1.29
第七步,计算加权后的基线平均值及相对疗效
#计算加权后IPD试验的结果
A.IPD %>%
summarise(outcome.mean=weighted.mean(outcome,wt),
outcome.sd=sqrt(sum(wt/sum(wt)*(outcome-outcome.mean)^2))
)
## # A tibble: 1 × 2
## outcome.mean outcome.sd
## <dbl> <dbl>
## 1 7.08 0.335
#汇总试验的结果
B.AgD[,c("y.B.bar","varB")]
## # A tibble: 1 × 2
## y.B.bar varB
## <dbl> <dbl>
## 1 7.4 0.2
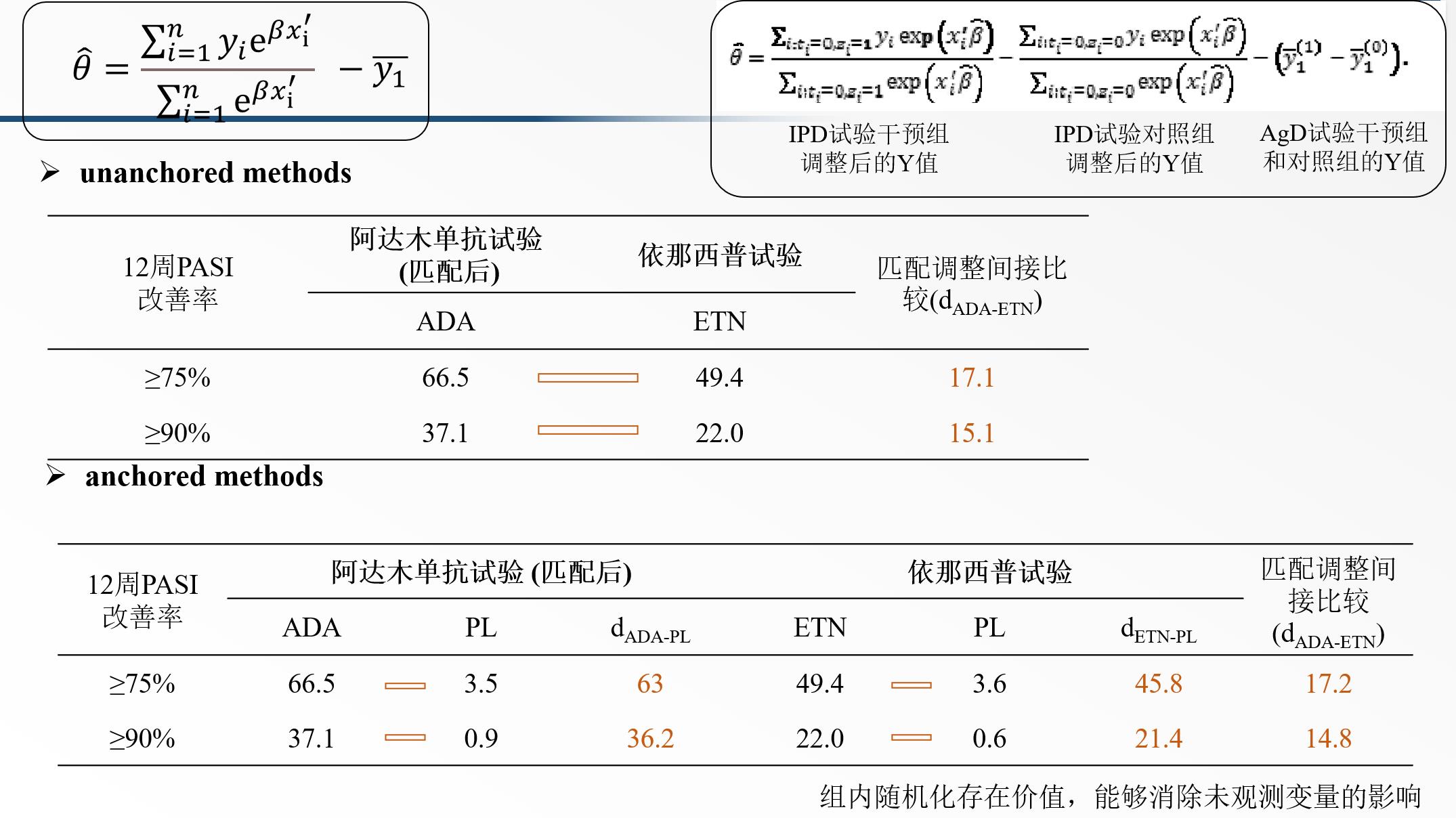
#相对疗效
outcome.mean<-c(7.084148)
y.B.bar<-c(7.4)
outcome.sd<-c(0.3350903)
y.B.sd<-c(0.2)
print(d.AB.MAIC<-outcome.mean-y.B.bar)
## [1] -0.315852
print(var.d.AB.MAIC<-outcome.sd+y.B.sd)
## [1] 0.5350903
[1] SIGNOROVITCH J E. WU E Q. YU A P. 等. Comparative effectiveness without head-to-head trials: a method for matching-adjusted indirect comparisons applied to psoriasis treatment with adalimumab or etanercept[J]. Pharmacoeconomics, 2010, 28: 935-945.
[2] NICE DSU. Population-adjusted indirect comparisons (MAIC and STC)[M/OL]. 2016. https://www.sheffield.ac.uk/nice-dsu/tsds/population-adjusted.