随机数
一、随机数的抽样方法
逆变换法
如何在指定分布中抽取随机数是本节关注的重点。
逆变换法就是把均匀分布X ~ U(0,1)中抽取的随机数,映射到指定累计分布中抽取随机数的一个过程。在这个过程中,我们首先求累积分布函数(CDF)的逆,也就是CDF的反函数,然后抽取均匀分布X ~ U(0,1)的一个随机数,带入反函数中,即可返回相应的随机数值。
其实具体数学原理和证明我也没有理解的特别清晰,可以参考 XXX XXX。待补充
二、特定分布抽取随机数
接下来我们看一下具体如何抽取随机数,以及在R和Excel中的实现。
单变量正态分布
R直接调用函数:
rnorm(n = 1,mean = 1,sd = 1) #分别为随机数个数,均值和标准差
Excel直接调用函数:
NORM.INV(RAND(),mean,SD) #分别为概率,均值和标准差
多元正态分布
Python直接调用函数:
np.random.multivariate_normal(mean=mu,cov=sigma,size=num) #均值,协方差矩阵,样本个数
R直接调用函数:
vcov(model) #先利用vcov函数得到协方差矩阵
t(chol(vcov(model))) #利用chol函数进行Cholesky分解
随机数向量 = 均值向量 + Cholesky分解矩阵 × 标准正态分布向量
Excel
先利用R得到Cholesky分解矩阵,再利用如下公式
随机数向量 = 均值向量 + Cholesky分解矩阵 × 标准正态分布向量
2.1 Weibull分布
Weilbull分布的CDF为
$$ f(x)=1- e^{- (\frac{x}{\beta})^{\alpha}}; \quad for \quad x\ge 0,\alpha>0,\beta>0 $$ 用逆变换法,我们产生Weibull分布随机数x的算法如下:
- 产生均匀分布的随机数u,即u ~ U(0,1);
- 计算$x=\beta(-ln(u)^{1/\alpha})$,其中x是随机数,u是累积分布函数。
软件实现:
R的自定义函数:
weibull_gen = function(n=1,alpha=1,beta=1){
u=runif(n = n) #n代表要生成随机数的个数,u是累积分布函数的取值,0-1之间
x = beta * (-log(u))^(1/alpha) #CDF进行逆变换,生成符合weibull分布的随机数
return(x)
}
weibull_gen(n = 10000,alpha = 2,beta = 7) #生成1000个shape(alpha)=2,scale(beta)=7的weibull分布的随机数
R直接掉包:
library(flexsurv)
qweibull(runif(10000), shape = 1.1354, scale = 704.1561)
Excel自定义函数:
beta * (-LN(RAND( )))^(1/alpha),其中beta和alpha是特定数字
#如:704.1561*(-LN(RAND()))^(1/1.1354)
Excel直接调用函数:
WEIBULL_INV(0.1,2,2) #excel的α和β参数就是R中的shape和scale
2.2 指数分布
Weilbull分布的CDF为
$$ f(x)=1- e^{-\lambda x}; \quad for \quad x\ge 0,\alpha>0 $$ 用逆变换法,我们产生指数分布随机数x的算法如下:
- 产生均匀分布的随机数u,即u ~ U(0,1);
- 计算$x=-\frac{ln(1-u)}{\lambda}$。
软件实现:
R的自定义函数:
exp_gen = function(n=1,lamda=1){
u= runif(n = n)
x= - log(1-u) /lamda
return(x)
}
rand_my =exp_gen(n = 100000,lamda = 4)
R直接掉包:
rand_fun=rexp(n = 100000,rate = 4)
Excel自定义函数:
和R一样,懒得写了。
Excel直接调用函数:
EXPON_INV(0.1,2) ##excel中的lamda参数就是r中的rate
2.3 log-normal(对数正态)分布
首先产生正态分布的随机变量y,然后通过$x=e^y$变换,产生对数正态分布的随机变量x。
软件实现:
R的自定义函数:
log_normal_gen = function(n=1,ln_mean=1,ln_sd=1){
y = rnorm(n = n,mean = ln_mean,sd = ln_sd)
x= exp(y)
return(x)
}
rand_my = log_normal_gen(n = 10000,ln_mean = 5,ln_sd = 2)
R直接掉包:
rand_fun=rlnorm(n = 10000,meanlog = 5,sdlog = 2)
Excel直接调用函数:
LOGNORM.INV(0.1,2,3) ##参数和R是对应的
2.4 log-logistic分布
log-logistic分布的CDF为
$$ f(x)=1- \frac{1}{(1+(\frac{x}{\beta})^\alpha)}; \quad for \quad x\ge 0,\alpha>0,\beta>0 $$ 用逆变换法,我们产生指数分布随机数x的算法如下:
CDF的反函数为 $$ x=\beta \sqrt[\alpha]{\frac{1}{1-u}-1} $$
软件实现:
R的自定义函数:
log_logistic_gen <- function(n=1,a,b){
u=runif(n = n)
x= b * ( (1/(1-u)) -1) ^ (1/a)
return(x)
}
rand_my = log_logistic_gen(n = 10000,a = 2,b=2)
R直接掉包:
rand_fun = flexsurv::rllogis(n = 10000,shape = 2,scale = 2)
Excel自定义函数:
beta*( (1/(1-RAND()))-1 )^(1/alpha) ##alpha和beta分别是参数值
Excel直接调用函数: 好像还没有直接的API接口。
2.5 贡伯兹(Gompertz)分布
Gompertz分布的CDF为
$$ f(x)=1- exp[-\frac{\beta}{\alpha}(e^{\alpha x}-1)]; \quad for \quad x\ge 0,\alpha>0,\beta>0 $$ 用逆变换法,我们产生指数分布随机数x的算法如下:
CDF的反函数为 $$ x=\frac{ln(\frac{\beta-\alpha ln(1-u)}{\beta})}{\alpha} $$
软件实现:
R的自定义函数:
gen_gomp <- function(n=1,a,b){
u=runif(n = n)
numerator = (b-a*log(1-u))/b
x= log(numerator)/a
return(x)
}
rand_my = gen_gomp(n = 10000,a = 2,b=2)
R直接掉包:
rand_fun = flexsurv::rgompertz(n = 10000,shape = 2,rate = 2)
Excel自定义函数:
LN((beta-alpha*LN(1-RAND()))/beta)/alpha ##alpha和beta分别是参数值
Excel直接调用函数: 好像还没有直接的API接口。
2.6 gamma分布
gamma分布的CDF的反函数没有解析解,不能使用逆变换法。
软件实现:
R直接掉包:
rand_fun = rgamma(n = 10000,shape = 2,rate = 3)
ExcelExcel直接调用函数:
GAMMA.INV(RAND(),alpha,beta) ##注意,excel中alpha对应r中的shape,beta参数是r中rate参数的倒数
2.7 广义gamma分布
补充知识:
$$ gamma \ function: \Gamma (z) = \int_0^{\infty} x^{z-1}e^{-x} dx $$
$$
lower \ incomplete \ gamma \ function: \gamma (s,x)=\int_0^xt^{s-1}e^{-t} dt
$$
$$
upper \ incomplete \ gamma \ function: \Gamma_x (s,x)=\int_x^{\infty} t^{s-1}e^{-t} dt
$$
excel求gamma函数值
Γ(z) = GAMMA(z)
γ(s, x) = EXP(GAMMALN(s)) * GAMMA.DIST(x, s, 1,TRUE)
Γ(s, x) = EXP(GAMMALN(s)) * (1 – GAMMA.DIST(x, s, 1,TRUE))
Gamma分布的生存函数= 1-EXP(GAMMALN(a))*GAMMA.DIST(b*t,a,1,TRUE)/GAMMA(a)
广义gamma分布的CDF的反函数没有解析解,不能使用逆变换法。 软件实现:
R直接掉包:
rand_fun = flexsurv::rgengamma(n = 1000,mu = 1,sigma = 1,Q = 1)
Excel中暂时没找到如何实现。有知道的小伙伴可以给我发邮件哟。
2.8 Royston-Parmar splines分布
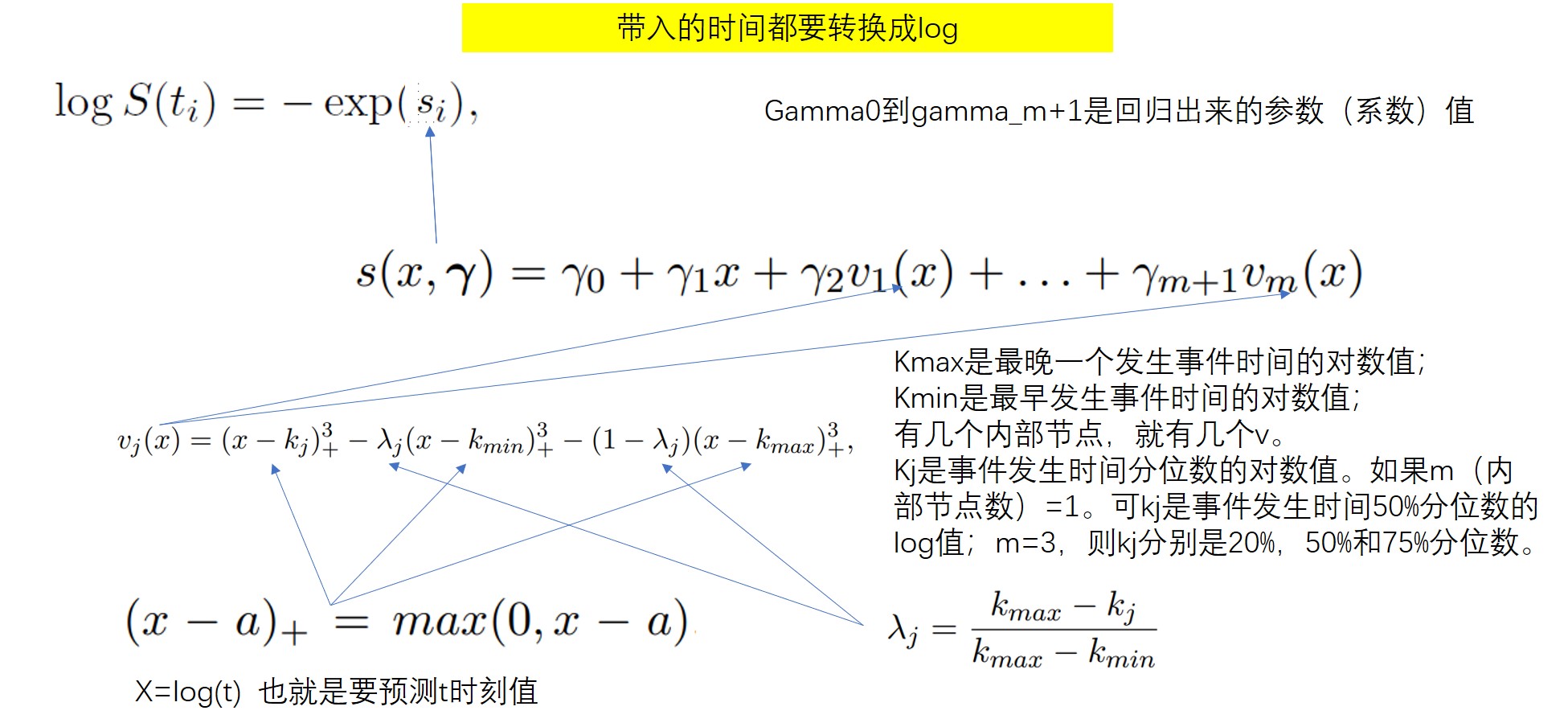
R直接掉包:
rand_fun = flexsurv::rsurvspline(n = 100,gamma = c(-12.17714,1.947243,0.3495745),knots = c(log(59),log(359),log(638)))
参考:
-
生存函数:https://devinincerti.com/2019/06/18/parametric_survival.html
-
Gamma函数: https://real-statistics.com/other-key-distributions/gamma-function/gamma-function-advanced/