2 基础语法
2.1 数据结构
2.1.1 向量(一维数据)
2.1.1.1 向量的创建方式
2.1.1.1.4 使用seq函数生成等差序列的向量
seq函数的原型是
seq(from=1,to=1,by=((to-from)/(length.out - 1)),length.out = NULL,along.with = NULL,...)
其中,from是首项,默认为1;to是末项,默认为1;by是步长或等差增量,可以为负数;length.out是向量的长度;along.with:用于指明该向量与另外一个向量的长度相同,along.with后应为另外一个向量的名字。
2.1.1.1.5 使用rep函数创建重复序列的向量
rep函数可以将某一向量重复若干次,该函数的原型如下:
rep(x , times = 1, length.out = NA, each = 1)
参数中,x为要重复的序列对象;times为重复的次数,默认为1;length.out为产生的向量长度,默认为NA(未限制);each为每个元素重复的次数,默认为1。
r1 <- rep(1:3,2)
r2 <- rep(1:3, each =2)
r3 <- rep(c(2,5),c(3,4)) #输出2 2 2 5 5 5 5 5将向量c(2, 5)按照后面给出的次数向量依次重复3次和4次
r4 <- rep(c(2,4,6),each=2 ,length.out = 5)## [1] 1 2 3 1 2 3
## [1] 1 1 2 2 3 3
## [1] 2 2 2 5 5 5 5
## [1] 2 2 4 4 62.1.2 时间日期
日期时间值通常以字符串形式传入R 中,然后转化为以数值形式存储的日期时间变量。
R 的内部日期是以1970 年1 月1 日至今的天数来存储,内部时间则是以1970 年1 月1 日至今的 秒数来存储。
tidyverse 系列的lubridate 包提供了更加方便的函数,生成、转换、管理日期时间数据,足以代替R 自带的日期时间函数。
2.1.3 识别日期时间
## Loading required package: timechange##
## Attaching package: 'lubridate'## The following objects are masked from 'package:base':
##
## date, intersect, setdiff, union## [1] "2023-11-27"## [1] "2023-11-27 15:58:13 CST"## [1] "2023-11-27 UTC"## [1] "2023-11-27"无论年月日/时分秒按什么顺序及以什么间隔符分隔,总能正确地识别成日期时间值:
## [1] "2020-03-01"## [1] "2020-03-01"## [1] "2020-01-03"## [1] "2020-03-01 12:13:00 UTC"注:根据需要可以ymd_h/myd_hm/dmy_hms 任意组合;可以用参数tz =“…” 指定时区。
也可以用make_date() 和make_datetime() 从日期时间组件创建日期时间:
## [1] "2020-08-27"## [1] "2020-08-27 21:27:15 UTC"2.2 控制结构
编程中的控制结构,是指分支结构和循环结构。
2.2.1 分支结构
正常程序结构与一步一步解决问题是一致的,即顺序结构,过程中可能需要对不同情形选择走不同的支路,即分支结构,是用条件语句做判断以实现分支:
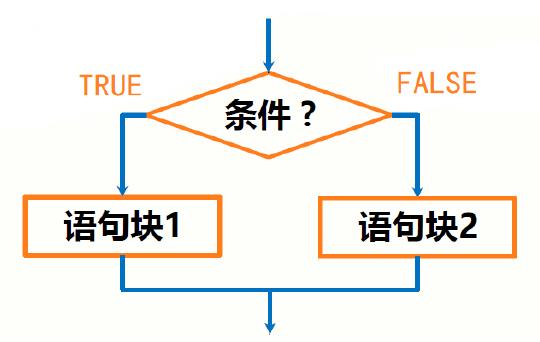
图2.1: 分支结构
1.一个分支
2.两个分支
例如,实现计算|x|:
3.多个分支
例子:实现将百分制分数转化为五级制分数
if(score >= 90) {
res = " 优"
} else if(score >= 80) {
res = " 良"
} else if(score >= 70) {
res = " 中"
} else if(score >= 60) {
res = " 及格"
} else {
res = " 不及格"
}另一种多分支的写法是用switch(),不推荐。一般用于自定义函数时,若需要根据参数不同指示值执行不同代码块,见:§2.4.1.1节。
函数ifelse() 可简化代码,仍以计算|x| 为例:
2.2.2 循环结构
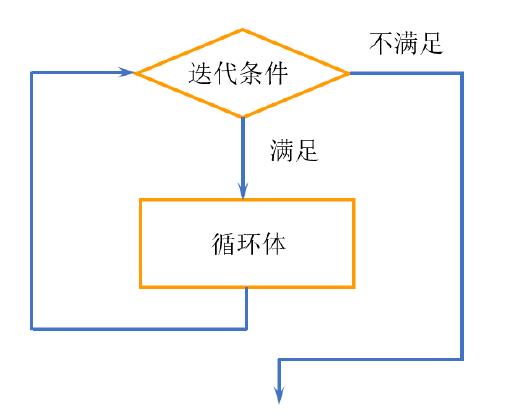
图2.2: 循环结构
2.2.2.1 for循环
例子:计算iris前四列的均值
df = as_tibble(iris[,1:4])
output = vector("double", 4) # 1. 输出
for (i in 1:4) { # 2. 迭代器
output[i] = mean(df[[i]]) # 3. 循环体
}
output## [1] 5.843333 3.057333 3.758000 1.199333for 循环有三个组件:
输出:output = vector(“double”, 4) 在循环开始之前,最好为输出分配足够的存储空间,这样效率更高:若每循环一次,就用c() 合并一次,效率会很低下。通常是用vector() 函数创建一个给定长度的空向量,它有两个参数:向量类型(logical, integer, double, character 等) 、向量长度。
迭代器:i in 1:4 确定怎么循环:每次for 循环将对i 赋一个1:4 中的值,可将i 理解为代词it. 有时候会用1:length(df), 但更安全的做法是用seq_along(df) ,它能保证即使不小心遇到长度为0 的向量时,仍能正确工作。
循环体:output[i] = mean(df[[i]])
2.3 apply函数组
在 R 的基础包中有一类函数叫 apply, 包括 apply, lapply, sapply, vapply, mapply, replacate 等. 这些函数相同的地方都是接受一个 list, matrix 或者 data.frame 作为参数, 同时接受一个函数作为参数, 然后对数据的每一行或列都使用函数进行处理, 相当于 “把函数应用 (apply) 到每一个单元”.
2.3.1 apply
apply 函数本身的运算速度其实和 for loop 很接近, 但是由于其语句少, 结构简单, 并且在能够调用 vapply 等高效的函数地方进行调用, 在进行大量重复应用相同函数到同一个数据集的时候效率似乎要比 for loop 要高一些. apply 函数有三个主要参数: 一个是data数据集,array, matrix, data.frame, list 都可以; 一个是 MARGIN, MARGIN 为 1 的时候对 matrix的每一行运行函数, MARGIN 为 2 的时候对 matrix 的每一列运行函数, 如果是 array 则可能是更高维; 一个是要对数据集运行的函数.
apply(x, MARGIN, FUN, …)
- x:为数据对象(矩阵、多维数组、数据框) ;
- MARGIN:1 表示按行,2 表示按列;
- FUN:表示要作用的函数
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6## [1] 3 4## [1] 1.5 3.5 5.5## Sepal.Length Sepal.Width Petal.Length Petal.Width
## 5.843333 3.057333 3.758000 1.1993332.3.2 lapply
lapply() 函数是一个最基础循环操作函数,用来对vector、list、data.frame 逐元、逐成分、逐列分别应用函数FUN,并返回和x 长度相同的list 对象。其基本格式为:
lapply(x, FUN, …)
- x:为数据对象(列表、数据框、向量) ;
- FUN:表示要作用的函数。
## $Sepal.Length
## [1] 5.843333
##
## $Sepal.Width
## [1] 3.057333
##
## $Petal.Length
## [1] 3.758
##
## $Petal.Width
## [1] 1.1993332.3.3 sapply
sapply() 函数是lapply() 的简化版本,多了一个参数simplify,若simplify=FALSE,则同lapply(),若为TRUE,则将输出的list 简化为向量或矩阵。其基本格式为:
sapply(x, FUN, simplify = TRUE, …)
## Sepal.Length Sepal.Width Petal.Length Petal.Width
## 5.843333 3.057333 3.758000 1.1993332.3.4 vapply
sapply()会尝试对apply的结果进行简化,如果无法简化,则不进行简化,返回原始结果。与sapply()类似,vapply()也会对apply结果进行简化,vapply()的不同之处在于,它需要显式地指明所希望简化为的具体格式,如果无法简化为所指定的格式,则会给出Error。使用cls_vect <- sapply(flags, class) 可以得到flags中各列的类型名称,并简化为一个character型的vector,使用vapply()并指明结果格式为character(1) 可以得到相同的结果:
而如果希望通过vapplu()得到numeric(1) 的结果,会出现Error:
2.4 自定义函数
例子:百分制数字对应五级制分数
- 先梳理一般代码段
score <- 76
if (score >= 90) {
res <- " 优"
} else if (score >= 80) {
res <- " 良"
} else if (score >= 70) {
res <- " 中"
} else if (score >= 60) {
res <- " 及格"
} else {
res <- " 不及格"
}
res## [1] " 中"- 一般函数
Score_Conv <- function(score) {
if (score >= 90) {
res <- " 优"
} else if (score >= 80) {
res <- " 良"
} else if (score >= 70) {
res <- " 中"
} else if (score >= 60) {
res <- " 及格"
} else {
res <- " 不及格"
}
res
}- 向量化改进
法一:for循环
Score_Conv2 <- function(score) {
n <- length(score)
res <- vector("character", n)
for (i in 1:n) {
if (score[i] >= 90) {
res[i] <- " 优"
} else if (score[i] >= 80) {
res[i] <- " 良"
} else if (score[i] >= 70) {
res[i] <- " 中"
} else if (score[i] >= 60) {
res[i] <- " 及格"
} else {
res[i] <- " 不及格"
}
}
res
}
# 结果测试
score <- seq(50, 100, 10)
Score_Conv2(score = score)## [1] " 不及格" " 及格" " 中" " 良" " 优" " 优"法二:利用map 系列函数
## [1] " 不及格" " 及格" " 优"2.4.1 函数设置
2.4.1.1 设定默认参数
分别计算样本标准差和总体标准差。默认计算样本标准差。
MeanStd <- function(x, type = "sample") {
mu <- mean(x)
n <- length(x)
switch(type,
"sample" = {
std <- sqrt(sum((x - mu)^2) / (n - 1))
},
"population" = {
std <- sqrt(sum((x - mu)^2) / n)
}
)
list(mu = mu, std = std)
}
MeanStd(1:5)## $mu
## [1] 3
##
## $std
## [1] 1.581139